前言
最近学了很多有关爬虫的知识,就正好分别记录一下。这一篇文章主要介绍一下,如何在网站上爬到自己想要的内容。
网页构成
我们所看到的网页,主要是由三部分组成,分别是:
- HTML 静态页面
- CSS
- JavaScript 文件
HTML 文件是静态页面,它对应的是一个静态页面,主要是由一个个的标签构成,比如段落 p,超链接 a,图片 img 等标签,通过一个个的标签,经过浏览器编译后,就生成了页面。
但是,很多网页往往是十分精美好看的,排版的工作主要是由 CSS 文件完成,可以对页面的各个控件进行格式设置。
然后就是 js 文件。在很多网页中,我们都可以看到动态的信息,比如动图、会变化的文字等等,这些动态元素的生成就是由 js 文件来生成的。但是要注意的是,js 生成的结果并不会改变 HTML 文件的内容,这一点是很关键的。为了让用于更难的爬取到内容,现在的很多网站都不会把网页的一些重要内容放到 HTML 文件中,而都是会采用 js 文件生成的方式。
如何获取到想要的内容
因此,网页显示的内容,基本上只会来源于两类文件,分别是 HTML 和 JavaScript 文件。所以,如果我们想要获取到我们需要的内容,那么就是从 HTML 文件和 js 生成的文件里面去寻找。
那么如何获取文件呢?这个获取文件的过程,称为抓包。而找寻我们想要的内容的过程,就是找包的过程。浏览器自身就有着一个很强大且好用的抓包工具,就是开发者工具,快捷键是 F12. 有关开发者工具的具体使用方式,B 站上有很多视频,这里就不介绍使用方法了。
每个包其实就是向一个接口(API)发出请求,然后得到了一个响应。因此,当我们找到想要的包后,就根据这个包的请求方式,用代码模拟这个请求,从而得到响应内容,然后从响应内容中提取出想要的内容即可。
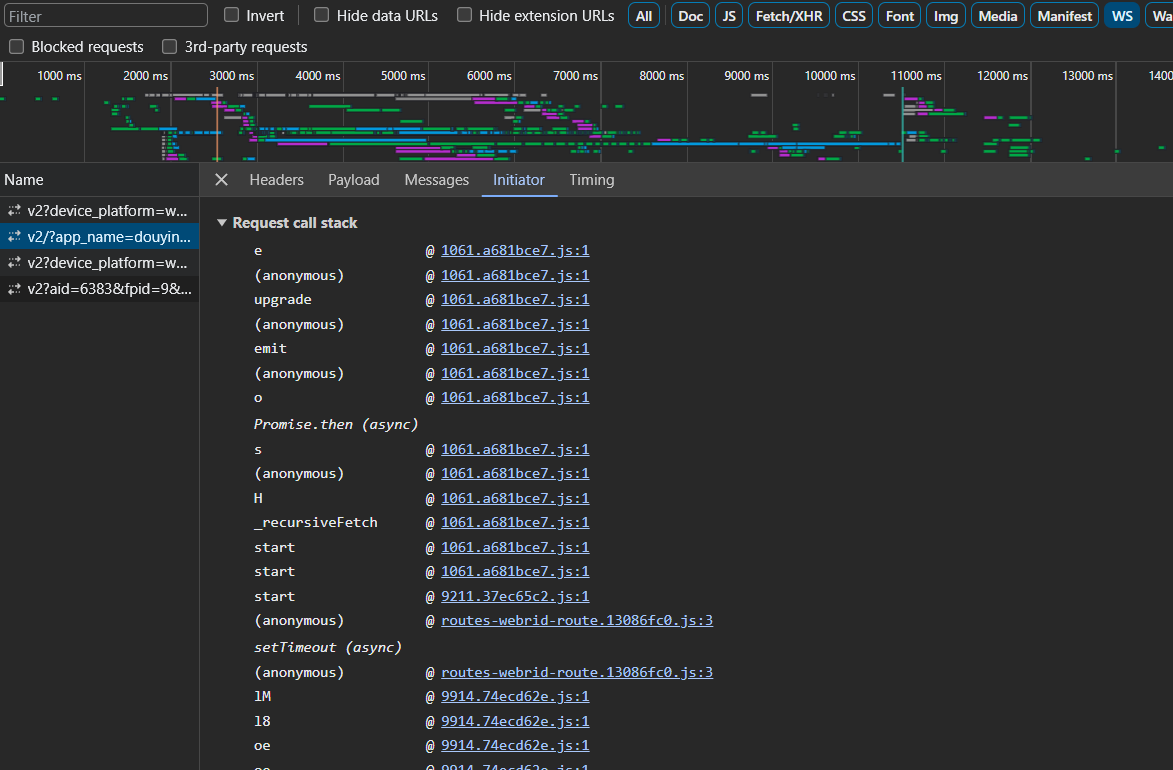
比如我们要爬取 B 站的表情包,抓了包之后,经过一番寻找,然后在下面的这个包中找到了含有表情包链接的包。
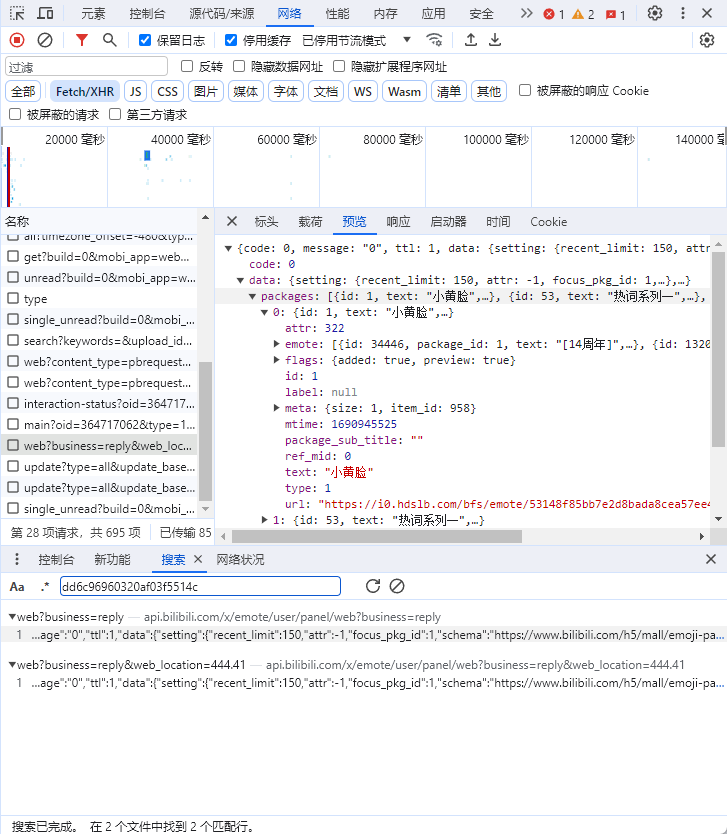
然后就可以在标头里,看到请求网址和请求方法,还有请求标头等信息。例如用 python 中的 requests 函数,就可以写:
request.get(
url='https://api.bilibili.com/x/emote/user/panel/web?business=reply&web_location=444.41',
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36',
'Referer': 'https://t.bilibili.com/?spm_id_from=333.1007.0.0'
}
)使用 get 方法,然后输入请求网址,以及请求头,就可以模拟浏览器,向该网址发出请求,然后得到响应。
值得注意的是,url 中问号后面的东西是请求参数,其中有时候,有一些参数并不是必要的,可以自己试一试,看看哪些是必要的,哪些可以去掉。
同时,headers 也是一样,并不需要把所有的都写上去,有些是可以去掉的。但是,User-Agent 是一定要带上的。在请求标头里,可以看到 cookie。有的网站会设置 cookie 反爬,这时请求头一定要带上 cookie 才能爬取到结果。并且,cookie 中也有很多的字段,有很多也是可以删掉的,往往只有一两个才是必要的。
如何从响应数据中提取内容
HTML
如果响应数据是 HTML 文件,那么提取的方式主要由两种,分别是 xpath 和正则表达式提取。先说正则表达式吧,这个更好理解。
正则表达式
首先,我们将返回的 HTML 文件转换成字符串,在 python 中,就是可以采用 request.get(xxxxxx).text text 方法,将响应数据转换为字符串。而从字符串中提取内容,就很容易想要用正则表达式了。然后也可以结合字符串的一些处理函数,一起提取内容。
正则表达式的用法我就不解释了,网上有很多教程,主要是如果你不经常用,是很难记住的,更好的方式是借助一些网站,然后通过查手册,边写边测试。这里推荐一个网站:https://regex101.com/
xpath 提取
与正则表达式提取方法不同,xpath 提取是专门针对于 HTML 文件的。首先,我们将响应数据转换成 HTML 格式后,根据页面标签的属性,定位到想要的内容所在的标签,然后将其提取出来。比如要获取 B 站的粉丝数,通过定位,知道了粉丝数所在的位置,如下:
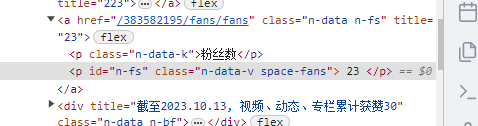
这时我们可以选中 23 所在的行,右键,在弹出的菜单里,选择 copy,然后就可以看到有一个 Copy XPath。然后就可以很方便的得到该 p 标签所对应的 XPath 了,即 //*[@id="n-fs"]。这个也很好理解,就是找 id 为"n-fs"的标签。由于这个 id 是唯一的,因此可以很精准的定位到粉丝数这里。而定位到 p 标签后,如果提取该标签内的文本呢?我们可以利用 text 方法,得到文本,即 //*[@id="n-fs"]/text()。
其他关于 XPath 更详细的语法,可以去网上找,这个和正则表达式一样,理解了原理之后,语法就是百度很容易解决的问题了。
JSON
在前面的表情包的例子中,可以看到返回的数据,很类似于 python 中的字典,其实这是 json 数据,这时,我们可以直接使用 requests.get(xxxx).json() 将其转换为 python 中的字典,然后取出想要的值即可。
有关爬虫的想法
最近学了这么多,并且爬了好几个网站后,回过头来看爬虫,其实整个过程很简单,因为一个内容在网站中呈现出来了,那么该内容就肯定会在某一个响应数据里,或者说在某一个包里。那我们抓包后,理想情况下,我们肯定能够找到该数据所在的包。而找到后,无非就是用分析该包的请求数据了。
因此,难点并不是在找内容,而是在请求数据的部分。因为现在很多网站都设置了反爬机制,比如说 cookie 反爬(这个是比较难破解的),请求参数加密等。对于请求参数加密的网站,比如前面分享的网易云音乐爬取,这种我们就需要对得到这个加密参数的 js 文件进行分析,然后应用到我们的代码中,仿照着生成同样的加密参数。不过我在对好几个网站的爬取之后,发现加密参数逆向还是比较简单的,可以按照一个模板来做。
这篇文章就不写代码相关的内容了,我觉得跟爬虫相关的代码是很简单的,无非就是模拟浏览器发出请求,就用到了那几个函数,其他就是对数据进行处理了。下一篇写一些爬虫的案例,就先从 B 站开始吧。而且我觉得爬虫代码部分是很简单的,不会的话直接百度,就很容易看懂。如果想要代码,可以加我 QQ,我发给你(如果我能找到的话)。